-
[MongoDB] MongoDB 주요 기능NoSQL/MongoDB 2022. 3. 8. 10:52반응형
MongoDB Query
- C(Create)
- db.person.save({ ‘name’:’john’}); - R(Read)
- db.person.find() - U(Update)
- db.users.update({name:’Johnny’}, {name:’Cash’, languages:[‘english’]}) - D(Delete)
- db.users.remove({name:’Sue’});
MongoDB Index
- 다수 인덱스 설정 가능
- 복합 인덱스 지원
- 빠른 검색 지원
- 도큐먼트에 저장된 데이터와 중복 저장 문제
- 메모리가 부족한 시스템에서는 검색 속도 저하 문제
MongoDB 복제
- Master-Slave 구조 구성
- 데이터 복사본을 Slave에 배치
- Master 장애에 따른 데이터 손실 없이 Slave 데이터 사용 가능
- Master 장애가 발생했을 때, Slave에서 Master를 선출 가능(중단없는 서비스 가능)
- 데이터 손실을 최소화하기 위해 저널링 지원(MongoDB의 데이터 변화에 따른 모든 연산에 대한 로그 적재)
MongoDB Sharding
- 대용량의 데이터를 저장하기 위한 방법
- 소프트웨어적으로 데이터베이스를 분산시켜 처리하는 구조 - 샤딩 방식
- 데이터베이스가 저장하고 있는 테이블을 테이블 단위로 분리하는 방법
- 데이터베이스가 저장하고 있는 테이블 자체를 분할하는 방법 - 분산 데이터베이스의 전통적인 분할 3계층 구조 지원
- 응용 계층, 중개자 계층, 데이터 계층
- 응용 계층은 데이터에 접근하기 위해 중개자를 통해 모든 데이터의 입출력을 처리
- 추상화된 한개의 데이터베이스가 존재하는 것처럼 운용

응용 계층 - client
중개자 계층 - mongos, Config Servers
데이터 계층 - Shards
client에서 데이터 입출력을 mongos에게 요청하면 mongos는 Config Servers를 참고하여 각각의 Shards에 분산하여 저장하고, 다시 mongos가 Shard에 분산된 데이터를 합쳐서 전송하는 방식으로 운영MongoDB MapReduce
- 대용량의 데이터를 안전하고 빠르게 처리하기 위한 방법
- 데이터를 분산하여 연산하고 다시 합치는 기술
- 맵과 리듀스 단계로 나누어 처리하며, 사용자가 임의 코딩 가능
- 입/출력 데이터는 Key-Value 형태로 구성 - 한대 이상의 하드웨어를 활용하는 분산 프로그래밍 모델
- 분산을 통해 분할된 조각으로 처리한 다음, 다시 모아서 휠씬 짧은 시간에 계산을 완료 - 대용량 파일에 대한 로그 분석, 색인 구축 검색 등에 활용
- 일괄처리 방식으로 전체 데이터 셋을 분석할 필요가 있는 문제에 적합
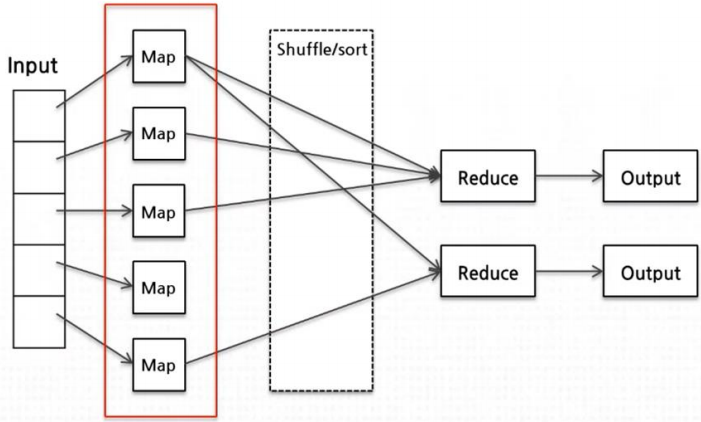
1.대용량에 Input 데이터를 일정한 크기로 나눈 후 각각에 Map 함수가 실행되는 서버로 병렬적으로 분산하여 처리
2.Map 함수를 독립적으로 실행되면 Input으로 들어온 데이터만 Output으로 생성
3.각각의 Output을 Shuffle을 통해서 Key 단위로 합친 후 Reduce를 실행하는 서버에 전달
4.Reduce는 하나의 키로 맞추어진 데이터들을 연산하여 최종 Output을 생성MongoDB 특징 : https://tychejin.tistory.com/348
MongoDB 장점/단점 : https://tychejin.tistory.com/349반응형'NoSQL > MongoDB' 카테고리의 다른 글
[MongoDB] Robomongo 3T - Database, Collection, Document 생성 및 조회 (1) 2022.03.10 [MongoDB] MongoDB 명령어 - Database, Collection, Document (0) 2022.03.08 [MongoDB] MongoDB 설치 및 환경 설정(Windows10) (0) 2022.03.08 [MongoDB] MongoDB 장점/단점 (0) 2022.03.08 [MongoDB] MongoDB 특징 (0) 2022.03.08 - C(Create)